ICASSP 2026 Oral
Open-world HOI
MLLM reasoning
Towards Open-World Human-Object Interaction Reasoning with Multimodal Large Language Model
Eastman Z. Y. Wu
Yali Li
Shengjin Wang *
Department of Electronic Engineering, Tsinghua University; Beijing National Research Center for Information Science and Technology (BNRist), China; National Engineering Research Center of Dangerous Articles and Explosives Detection Technologies, Beijing, China.
* Corresponding author.
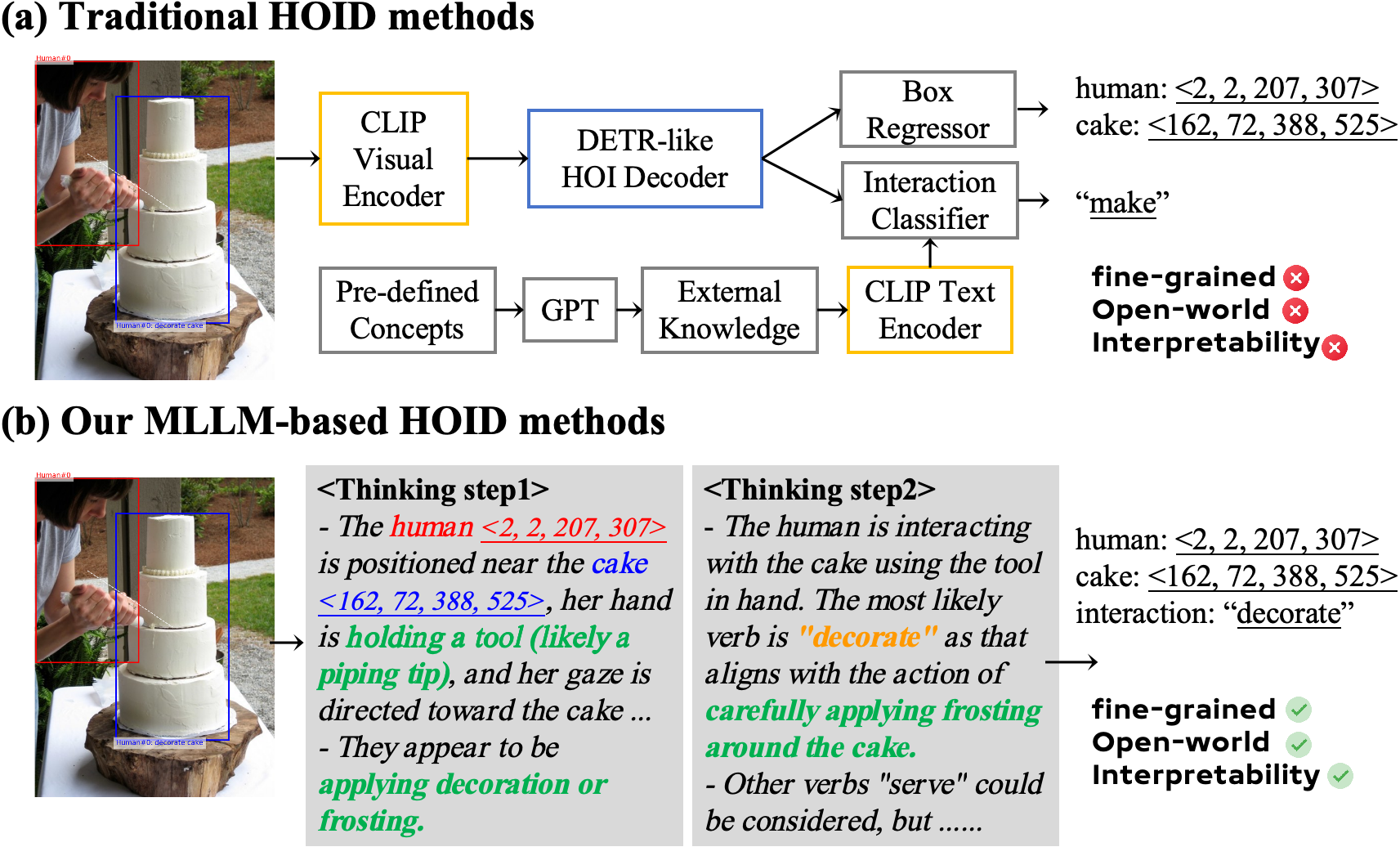
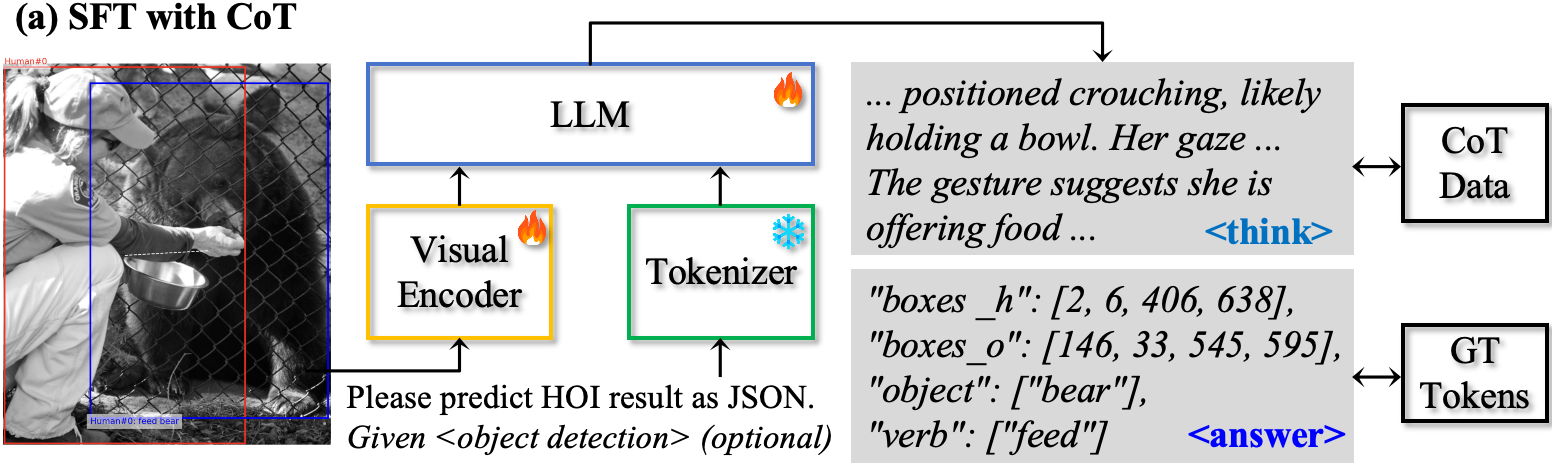
A reasoning-first HOI detector that produces structured predictions and human-readable instance-level explanations.
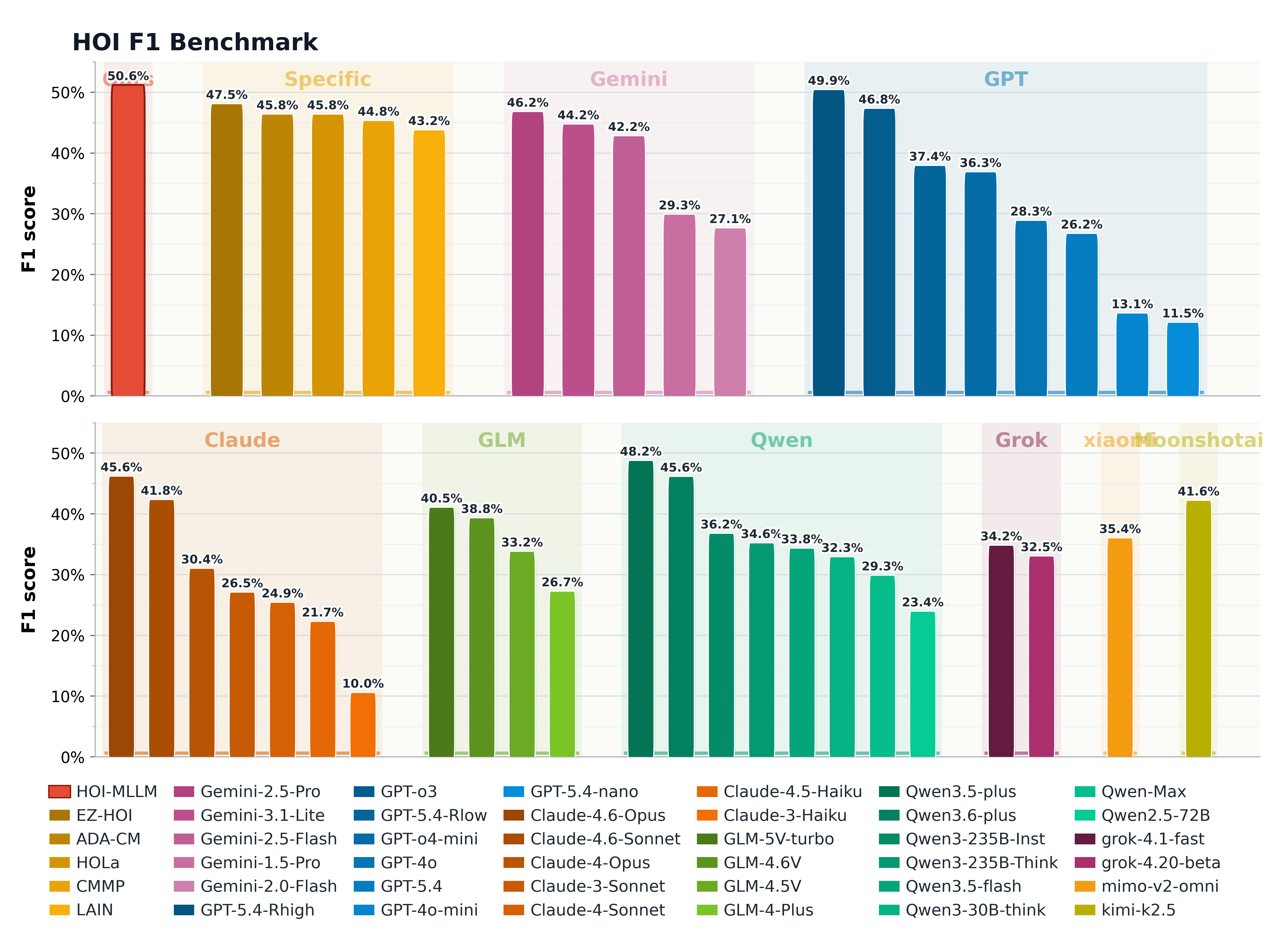
69.28
V-COCO R50-DETR mF1
50.61
HICO-DET Oracle mF1
Background photo:
Brooke Lark / Unsplash